PyTorch中的学习率调整策略
在训练模型时,学习率常常需要动态调整。对于不同的任务,需要针对性的设置学习率策略,才能让模型发挥最大潜力。
在PyTorch中,torch.optim.lr_scheduler接口提供了多种学习率调整方法,本文介绍了它们中一些常见的调整策略。
1. StepLR
torch.optim.lr_scheduler.StepLR(optimizer, step_size, gamma=0.1, last_epoch=- 1, verbose=False)
optimizer每迭代
“`step_size“`次,当前的学习率就乘以“`gamma“`。当“`last_epoch“`=-1时,学习率会从初始值开始。
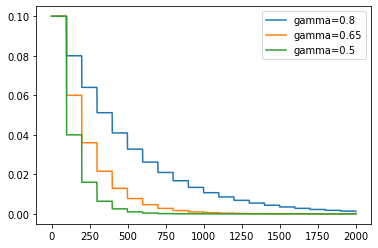
如图所示,不同的gamma值引起了不同程度的学习率衰减。
2. CosineAnnealingLR
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max, eta_min=0, last_epoch=-1, verbose=False)
对学习率进行余弦退火,以取得更好的训练结果。
“`T_max“`参数声明了最大的迭代次数,“`eta_min“`参数声明了学习率的最小值(默认为0)。

此图展示了当
“`T_max“`=300时学习率随迭代次数的变化。
3. LambdaLR
torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda, last_epoch=-1, verbose=False)
把当前学习率设置为初始学习率乘以自定lambda函数(对于迭代次数)的结果。
“`lr_lambda“`参数声明了自定函数。
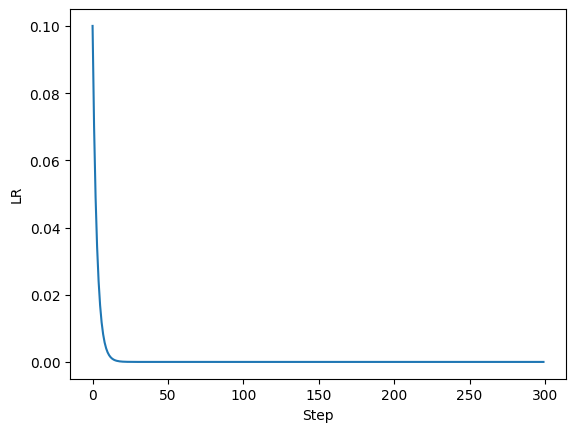
上图展示了当lambda函数为
lambda epoch: 0.7**epoch
时学习率随迭代次数的变化。
4. ConstantLR
torch.optim.lr_scheduler.ConstantLR(optimizer, factor=0.3333, total_iters=100, last_epoch=-1, verbose=False)
将当前学习率设置为初始学习率乘以
“`factor“`声明的系数,直到迭代次数达到了“`total_iters“`声明的目标次数。
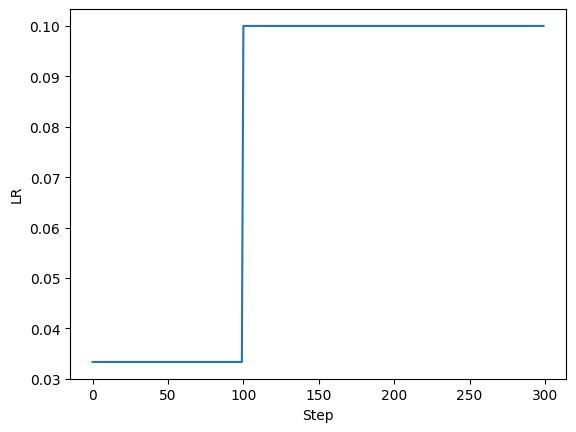
如图所示,在迭代次数到达100时,学习率恢复为初始学习率。在此之前,学习率被设置为初始学习率乘以0.3333。
5. LinearLR
torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=0.3333, end_factor=1.0, total_iters=100, last_epoch=-1, verbose=False)
将当前学习率设置为初始学习率乘以一个线性变化的系数,直到迭代次数达到了
“`total_iters“`声明的目标次数。“`start_factor“`声明了系数开始时的值,“`end_factor“`声明了系数结束时的值。
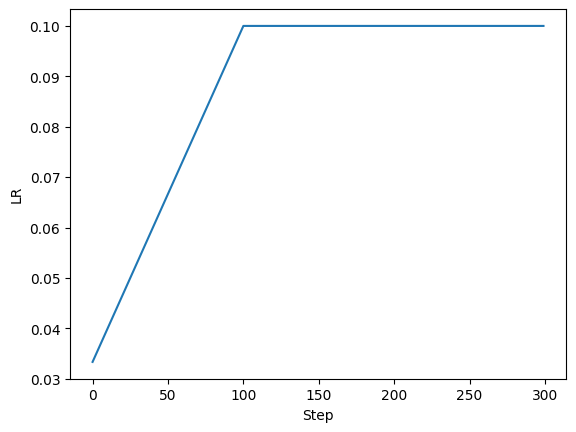
如图所示,在迭代次数到达100时,学习率恢复为初始学习率。在此之前,学习率乘以的系数从0.3333线性增长到1.0。
6. ExponentialLR
torch.optim.lr_scheduler.ExponentialLR(optimizer, 0.7, last_epoch=-1, verbose=False)
每次迭代都将学习率乘以衰减率
“`gamma“`,等同于step_size=1时的StepLR。
7. PolynomialLR
torch.optim.lr_scheduler.PolynomialLR(optimizer, total_iters=5, power=1.0, last_epoch=-1, verbose=False)
在
“`total_iters“`步内使用“`power“`次多项式将学习率降到0。
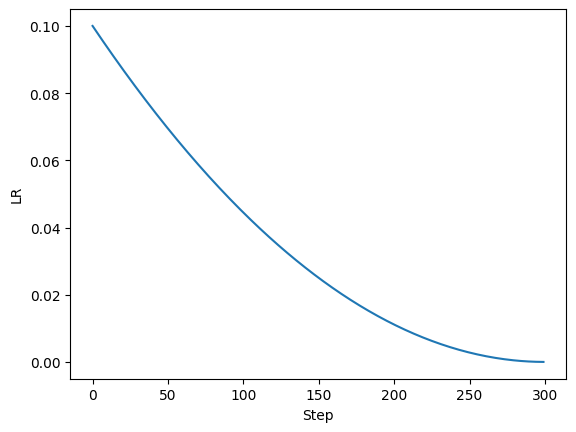
如图所示,学习率在300步内以二次函数的形式衰减至0。
8. SequentialLR
torch.optim.lr_scheduler.SequentialLR(optimizer, schedulers, milestones, last_epoch=-1, verbose=False)
按顺序使用一系列不同的调整策略来调整学习率。
“`schedulers“`声明了要使用的策略的列表,“`milestones“`声明了策略切换的位置。
9. ReduceLROnPlateau
torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08, verbose=False)
当指标停止改进时,降低学习率。当模型性能提升陷入停滞时,如果指标在
“`patience“`次迭代内没有改善,那么降低学习率。“`mode“`声明了指标改善的方式,max代表指标越高越好,min代表指标越低越好。“`factor“`声明了学习率衰减的倍率。“`threshold“`声明了指标改善的阈值,只有高于此值的变化会被认可为改进。“`threshold_mode“`声明了阈值的类型。“`cooldown“`声明了学习率降低后等待的迭代次数。“`min_lr“`声明了学习率的最小值。“`eps“`声明了学习率降低的阈值,如果降低幅度低于此值,将会被忽略。